Problem biznesowy
W 2022 roku aplikacja React Native była już rozwijana na tyle intensywnie, że obecny pipeline w Bitrise zaczął być realnym kosztem dla zespołu. Jeden build potrafił trwać blisko godzinę, a przy kilku poprawkach dziennie robiło się z tego regularne czekanie na informację zwrotną zamiast normalnej pracy.
Problem nie polegał wyłącznie na "wolnym CI". Długi build blokował QA, opóźniał release candidate'y i utrudniał reagowanie na pilne błędy. W praktyce nawet drobny hotfix potrafił zamienić się w pół dnia koordynacji, bo każdy kolejny build w Bitrise ustawiał się w kolejce za poprzednim.
Co zoptymalizowałem
Zacząłem od rozpisania najdroższych etapów pipeline'u. Szybko wyszło, że workflow robił zbyt wiele rzeczy naraz:
- na każdym uruchomieniu instalował od zera zależności JavaScript, Ruby, CocoaPods i Gradle,
- odpalał pełny zestaw kroków niezależnie od tego, czy chodziło o pull request, build QA czy release,
- wykonywał zbędne clean buildy,
- kilka razy powtarzał bundlowanie JavaScriptu i assetów.
Zamiast dokręcać pojedyncze śruby, przebudowałem cały przepływ:
- rozbiłem jeden ciężki workflow na osobne ścieżki dla PR-ów, buildów QA i pełnych release'ów,
- ustawiłem cache dla Yarn, Bundlera, CocoaPods i Gradle oparty o lockfile, żeby uniknąć niepotrzebnych cold startów,
- usunąłem
pod repo updatez codziennych buildów i zostawiłem tylko deterministycznepod install --deployment, - ograniczyłem buildy Androida do konkretnego wariantu zamiast budować zbędne flavor'y przy każdej zmianie,
- przeniosłem bundlowanie JS do jednego kontrolowanego kroku, eliminując podwójne generowanie bundle'a w skryptach release,
- zostawiłem pełne podpisywanie i eksport artefaktów tylko tam, gdzie naprawdę było potrzebne.
Decyzje techniczne
Największy zysk nie wynikał z jednej magicznej flagi, tylko z uporządkowania odpowiedzialności pipeline'u. Innego czasu potrzebuje walidacja pull requesta, innego build testerski, a innego pełny release do dystrybucji. Wcześniej te trzy scenariusze były wrzucone do jednego worka.
Po stronie Androida wykorzystałem cache Gradle i równoległe wykonywanie zadań tylko dla wymaganych wariantów. Po stronie iOS kluczowe było ustabilizowanie środowiska i cache dla Pods, żeby Bitrise nie odtwarzał za każdym razem kosztownej części builda. Dodatkowo dopilnowałem, żeby wersje Node, Ruby i stack Xcode były spięte na sztywno, bo wcześniej drobne rozjazdy środowiska niepotrzebnie unieważniały cache.
Ważne było też to, czego nie zrobiłem: nie wycinałem krytycznych zabezpieczeń jakościowych. Zamiast usuwać testy czy walidację, oddzieliłem je od kroków release'owych i uruchamiałem dokładnie tam, gdzie dawały największą wartość.
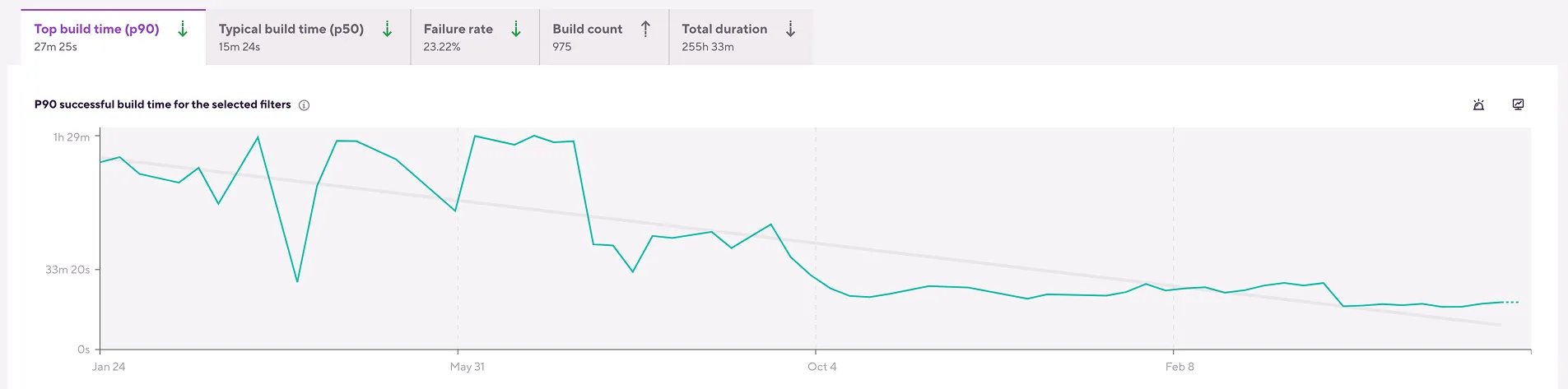
Efekt
Średni czas builda spadł z okolic 1 godziny do około 15 minut, czyli o 75%. To oznaczało nie tylko szybsze pipeline'y w dashboardzie Bitrise, ale przede wszystkim realną zmianę w pracy zespołu:
- QA dostawało wersje testowe tego samego dnia bez długiego czekania,
- hotfix przestawał być "operacją na pół dnia",
- release candidate'y można było przygotowywać znacznie częściej i z mniejszym kosztem koordynacyjnym.
To case study dobrze pokazuje, że w mobile performance nie kończy się na samej aplikacji. Czasem największą dźwignią dla zespołu jest uporządkowanie CI/CD tak, żeby programiści i QA przestali czekać na narzędzie, które powinno ich przyspieszać.